Modern NVIDIA GPUs are feats of hierarchical design, optimized to maximize parallelism, minimize latency, and deliver staggering computational throughput. Building upon Part 1, which introduced the high-level architecture of NVIDIA GPUs, this is Part2 – a Deep dive into GPU Compute Hierarchy: Graphics Processing Clusters (GPCs), Texture Processing Clusters (TPCs), Streaming Multiprocessors (SMs), and CUDA cores. Understanding this hierarchy is essential for anyone looking to write optimized CUDA code or analyze GPU-level performance.
1. Graphics Processing Clusters (GPCs)
1.1 Overview
At the top of NVIDIA’s compute hierarchy lies the Graphics Processing Cluster. A GPC is an independently operating unit within the GPU, responsible for distributing workloads efficiently across its internal resources. Each GPC contains a set of Texture Processing Clusters (TPCs), Raster Engines, and shared control logic.
📊 GPC Block Diagram:
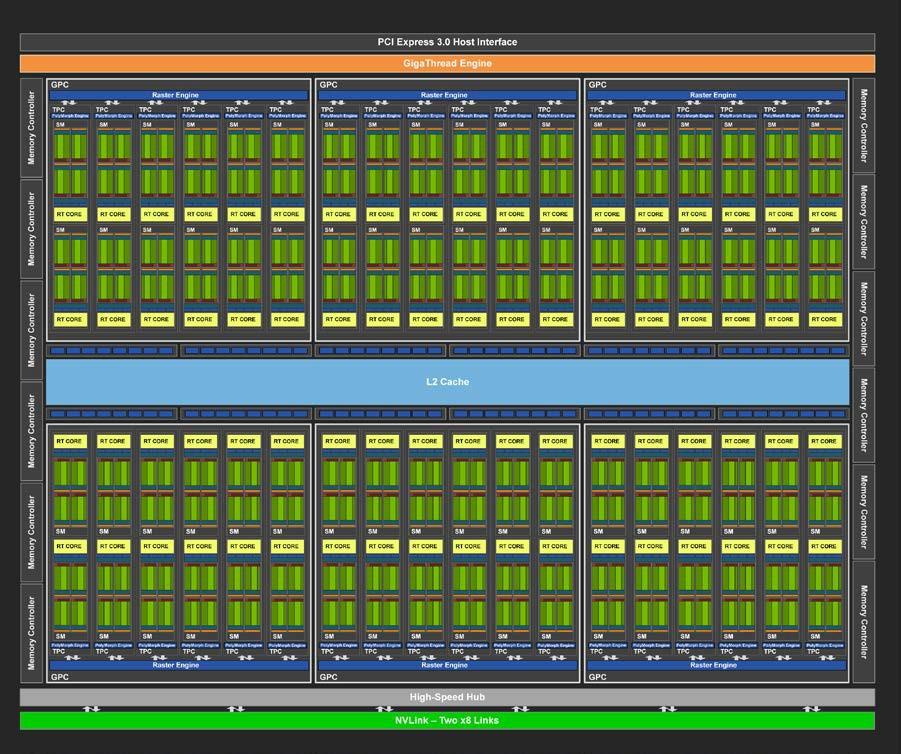

1.2 GPC Architecture
Each GPC includes:
- One or more Raster Engines
- Several TPCs (typically 2 to 8 depending on the GPU tier)
- A Geometry Engine (in graphics workloads)
📘 Example GPC layout in RTX 30 series:
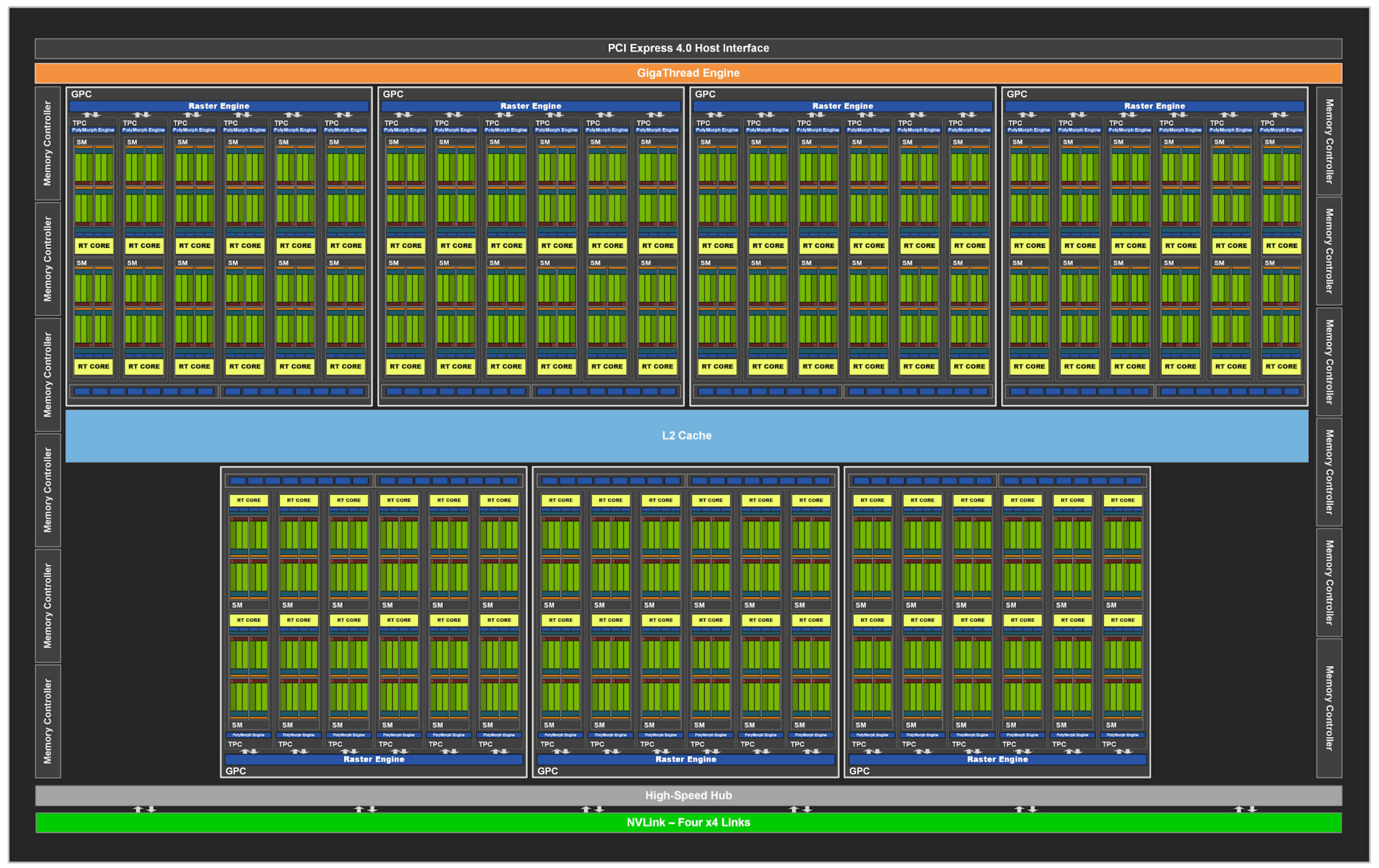
1.3 Scalability Role
More GPCs generally equate to more parallel compute and graphics capability. High-end GPUs like the H100 feature many GPCs to support large-scale AI workloads, while mobile GPUs may only include one or two.
2. Texture Processing Clusters (TPCs)
2.1 Role of TPCs
TPCs are the next level down. A TPC groups together Streaming Multiprocessors (SMs) and a set of fixed-function texture units, providing both compute and graphics acceleration. Originally optimized for texture mapping and rasterization, TPCs in modern GPUs support general-purpose compute as well.
2.2 Components of a TPC
Each TPC typically contains:
- Two Streaming Multiprocessors (SMs)
- Shared L1 cache
- Texture units (for graphics and compute shaders)
- A PolyMorph Engine (responsible for vertex attribute setup and tessellation)
📊 TPC Diagram with SMs and Texture Units:
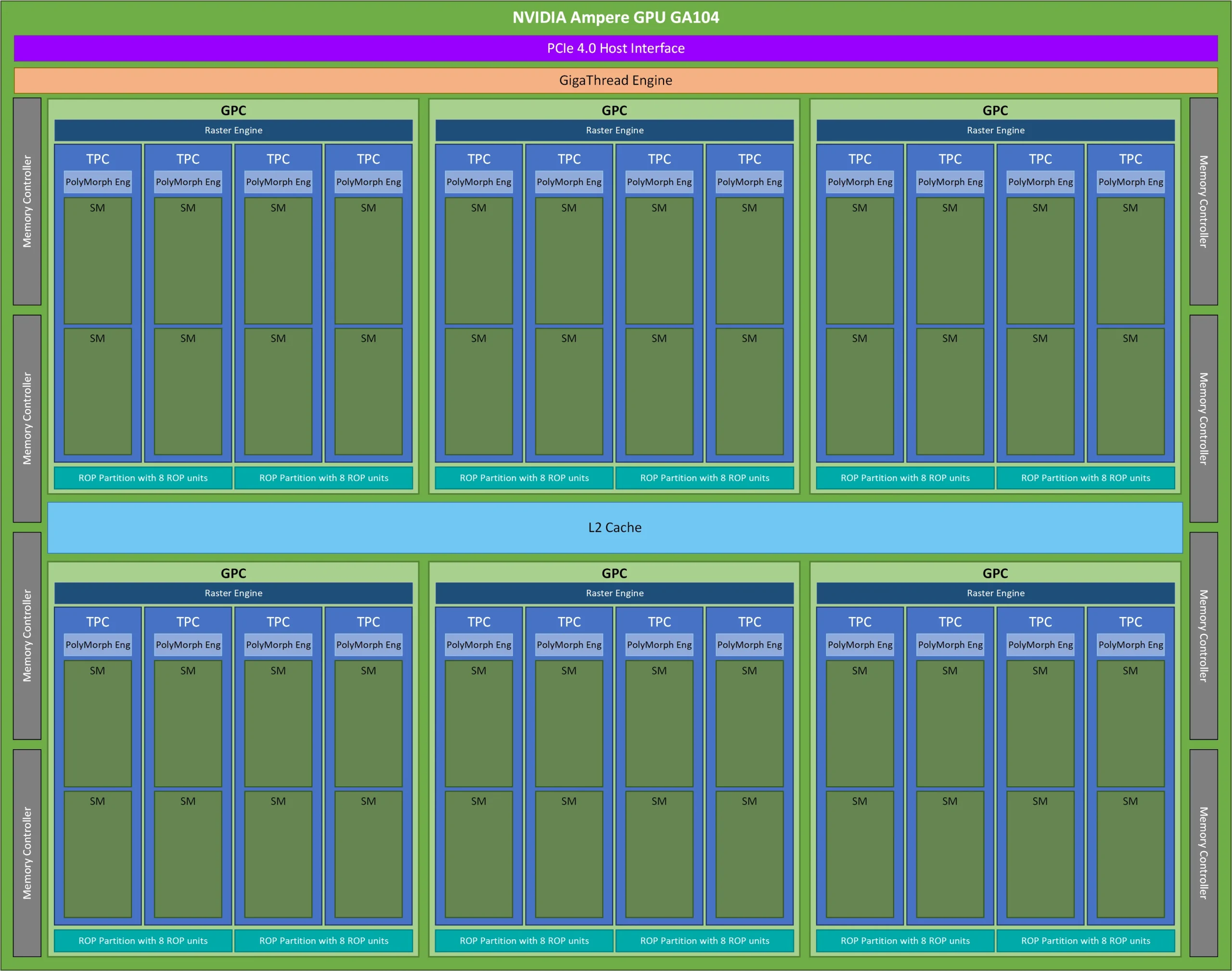
2.3 Texture Mapping
Texture units in the TPC fetch texels from memory, perform filtering (e.g., bilinear, trilinear), and handle texture addressing. These units have been extended to support texture sampling for compute workloads, such as in scientific visualization.
3. Streaming Multiprocessors (SMs)
3.1 Importance of SMs
Streaming Multiprocessors are the core programmable units of NVIDIA GPUs. They execute the majority of instructions, including floating-point arithmetic, integer operations, load/store instructions, and branch logic.
3.2 SM Internal Structure
A modern SM (e.g., in the Hopper H100 or Blackwell B100) consists of:
- Multiple CUDA cores (up to 128 per SM)
- Load/Store Units (LSUs)
- Integer and Floating Point ALUs
- Tensor Cores (for matrix operations)
- Special Function Units (SFUs)
- Warp schedulers and dispatch units
- Register files
- Shared memory and L1 cache
📘 SM Layout Reference (Volta/Hopper SMs):
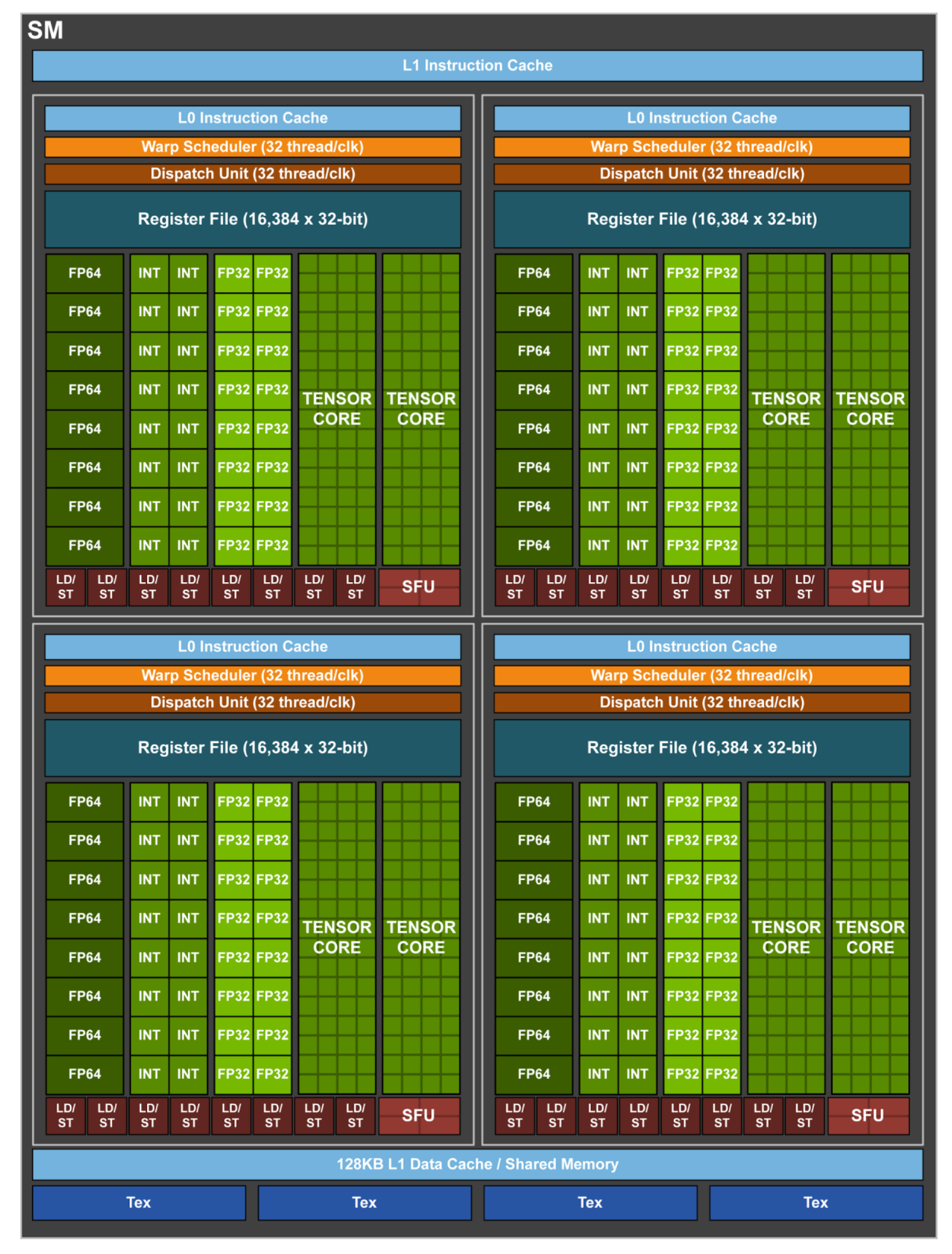
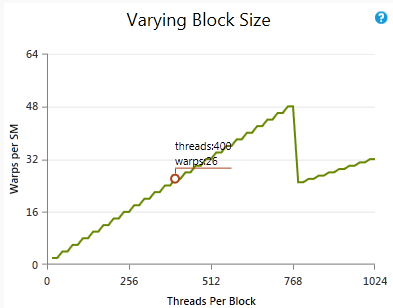
3.3 Warp Scheduling
The warp scheduler picks a ready warp from a warp pool and issues an instruction every clock cycle. Techniques like GTO (Greedy Then Oldest), Round-Robin, or Two-Level scheduling are used.
Key Benefits:
- Latency hiding: Warps can be swapped out when memory access stalls occur.
- Concurrency: Independent warps can issue instructions simultaneously.
4. CUDA Cores
4.1 Role of CUDA Cores
CUDA cores, also called SPs (Streaming Processors), are the smallest execution units. Each core executes a single thread from a warp, performing basic arithmetic and logic operations.
4.2 Arithmetic Logic Units (ALUs)
Each CUDA core consists of:
- FP32 FPU (Floating Point Unit)
- INT ALU (Integer Arithmetic Unit)
- Optional support for FP64, depending on SM design
4.3 SIMD Execution under SIMT Model
NVIDIA employs a SIMT (Single Instruction, Multiple Thread) model. Each warp executes one instruction at a time across 32 CUDA cores. Despite the SIMT term, the execution model is close to SIMD, with divergence managed by disabling inactive lanes.
4.4 Register Files and Local Storage
Each thread gets a set of registers from the SM’s register file. Efficient register usage is critical to avoiding spills to slower local memory.
5. Specialized Units within SMs
5.1 Tensor Cores
Tensor cores are designed to accelerate matrix multiplications—key in deep learning. They support:
- FP16, TF32, INT8, and FP4 (in Blackwell)
- Mixed-precision compute
- Fused Multiply-Add (FMA) operations on tiles of 4×4, 8×8 matrices
5.2 Special Function Units (SFUs)
SFUs compute transcendental functions like sine, cosine, exp, log, and square root. These are not time-critical in AI workloads but crucial in graphics.
5.3 Load/Store Units (LSUs)
LSUs manage memory operations between registers, shared memory, and L1/L2 caches. Optimizing memory throughput requires understanding how LSUs queue and coalesce memory transactions.
6. Summary and Practical Takeaways
Understanding the hierarchical breakdown of GPC → TPC → SM → CUDA core helps:
- Optimize kernel launch configurations
- Maximize warp occupancy
- Minimize divergence and memory stalls
- Align workloads with hardware capabilities
In the next part of the series, we’ll explore Tensor Cores and RT Cores in-depth—covering how NVIDIA has fused graphics and AI acceleration into a unified pipeline.