👋 Welcome to GPU Architecture 101
In this first post in five-part series, where I introduce you to the NVIDIA GPU architecture—a foundation for parallel computing used in gaming, scientific computing, artificial intelligence, and more.
This guide is designed for engineering students and beginner developers who want to understand how modern GPUs work—from their evolution to core architectural blocks like GPCs, TPCs, SMs, and CUDA Cores.
🧠 What is a GPU and Why Does It Matter?
A GPU (Graphics Processing Unit) is a processor specialized in performing many operations simultaneously. Unlike CPUs, which handle one or a few tasks at a time, GPUs contain thousands of smaller cores to process data in parallel.
A Quick Comparison: GPU vs CPU
| Feature | CPU | GPU |
|---|---|---|
| Focus | Serial processing | Parallel processing |
| Cores | 4–32 large cores | 100s–1000s of smaller cores |
| Usage | OS, logic, light apps | Graphics, AI, simulations |
📊 GPUs are ideal for matrix multiplications, image processing, 3D rendering, and training AI models.
🚀 NVIDIA GPU Architecture Hierarchy
Understanding the hierarchy inside a GPU is key to mastering performance tuning and CUDA programming.
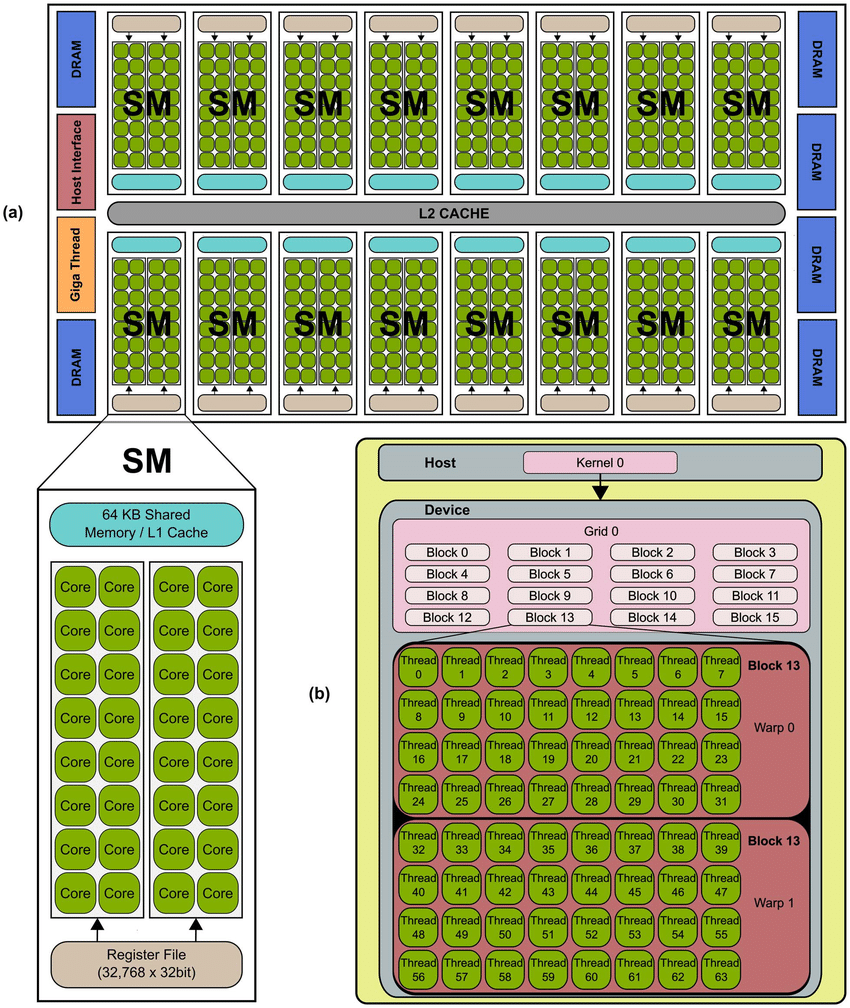
Levels of NVIDIA GPU Architecture (2025)
- Graphics Processing Cluster (GPC): Top-level cluster that contains TPCs and manages workload distribution.
- Texture Processing Cluster (TPC): Contains Streaming Multiprocessors (SMs) and texture units.
- Streaming Multiprocessor (SM): The computational engine with CUDA cores, registers, and cache.
- CUDA Cores: The smallest processing unit in NVIDIA GPUs.
Each layer is optimized for massive parallelism and throughput.
🔁 The Grid: How GPU Threads Are Organized
In CUDA, threads are organized into:
- Threads: Single instruction executors
- Warps: 32 threads grouped for SIMT (Single Instruction, Multiple Threads) execution
- Blocks: Collections of warps
- Grids: Collections of blocks
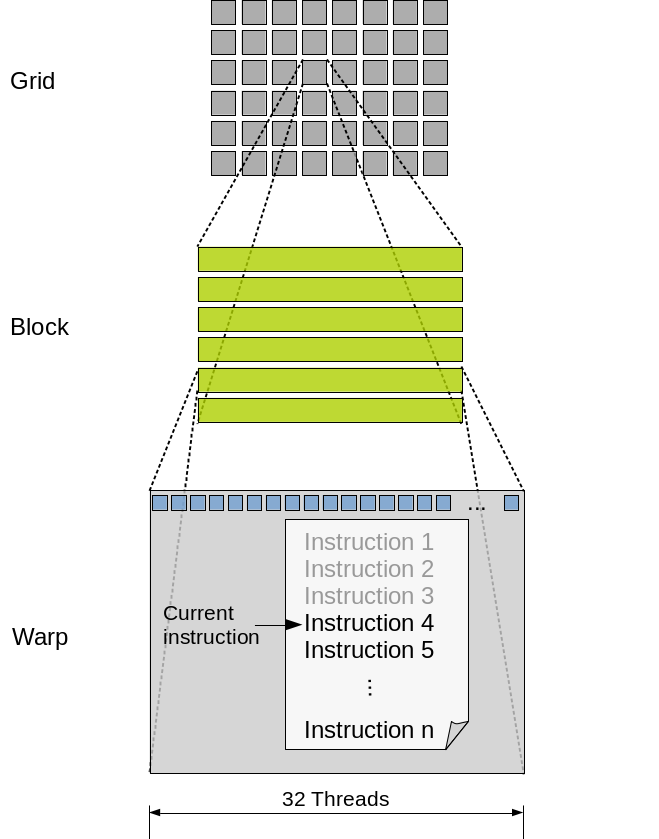
📌 SIMT is not the same as SIMD. In SIMT, threads may diverge, allowing for more flexible execution.
This structure is why GPUs scale so well—from a GTX 1650 to an A100 or H100—by just increasing the number of SMs and CUDA cores.
⚙️ CUDA Cores: The Heart of the NVIDIA GPU
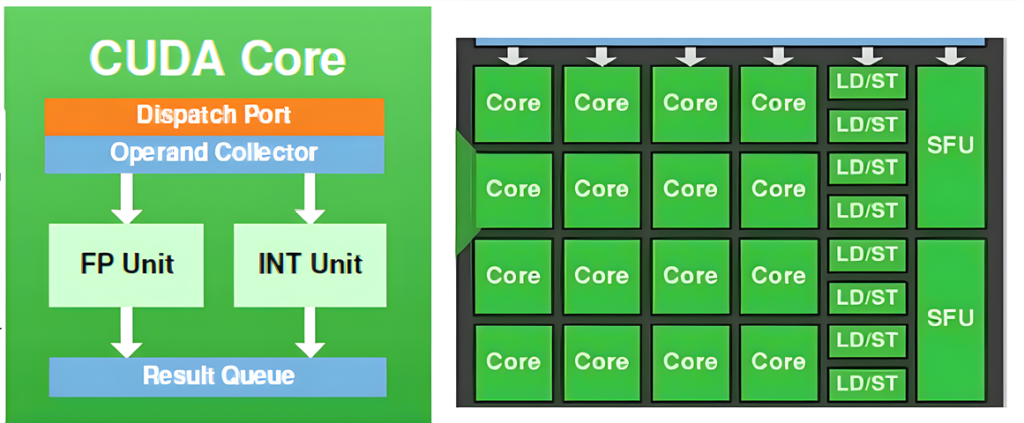
Each CUDA Core performs:
- Integer operations via ALU
- Floating-point operations (FP32, FP16)
- Memory access operations via load/store units
- Instruction decoding and execution
Example structure inside a CUDA core:
- ALU (Arithmetic Logic Unit)
- Register file
- Instruction decoder
- Control logic
These cores execute in parallel across warps under SIMT, boosting throughput for matrix-heavy tasks like image filters or neural network inference.
👨💻 Programming with CUDA (Hello World)
NVIDIA provides CUDA, a C/C++-like language for writing GPU code. Here’s a simple CUDA kernel to add two vectors:
cCopyEdit__global__ void vectorAdd(float *A, float *B, float *C, int N) {
int i = threadIdx.x + blockIdx.x * blockDim.x;
if (i < N) C[i] = A[i] + B[i];
}
__global__: Marks a function as a GPU kernel.threadIdx,blockIdx, andblockDim: Built-in variables that locate threads in the grid.
This model maps well to the GPU’s architecture, where thousands of threads execute in parallel.
📌 Summary
- NVIDIA GPUs are designed for parallel processing using a hierarchical architecture.
- The architecture scales from GPC → TPC → SM → CUDA cores.
- CUDA enables direct access to GPU hardware through a thread-block-grid model.
- Understanding SIMT, warps, and memory layout is key to efficient GPU programming.
I blog about latest technologies including AI / ML, Audio / Video, WebRTC, Enterprise Networking , automotive and more. In the next blog, we’ll explore GPCs, TPCs, and SMs in-depth—including scheduling, caches, and warp control. Follow my blog here and on Linkedin.