Rust is a multi-paradigm, general-purpose programming language exploding in popularity. But what makes it special? Rust offers a unique blend of blazing speed, unparalleled memory safety, and powerful abstractions, making it ideal for building high-performance, reliable systems. This blog delves into the Rust Programming Language learning roadmap
Why Embrace Rust?
- Unmatched Performance: Rust eliminates the need for a garbage collector, resulting in lightning-fast execution and minimal memory overhead. This makes it perfect for resource-constrained environments and applications demanding real-time responsiveness.
- Rock-Solid Memory Safety: Rust enforces memory safety at compile time through its ownership system. This eliminates entire classes of memory-related bugs like dangling pointers and use-after-free errors, leading to more stable and secure software.
- Zero-Cost Abstractions: Unlike some languages where abstractions incur performance penalties, Rust achieves powerful abstractions without sacrificing speed. This allows you to write expressive, concise code while maintaining peak performance.
Language Fundamentals: Understanding the Building Blocks
Syntax and Semantics: Rust borrows inspiration from C-like languages in its syntax, making it familiar to programmers from that background. However, Rust’s semantics are distinct, emphasizing memory safety through ownership and immutability by default.
Constructs and Data Structures: Rust offers a rich set of control flow constructs like if, else, loop, and while for building program logic. Data structures encompass primitive types like integers, booleans, and floating-point numbers, along with powerful composite types like arrays, vectors, structs, and enums.
Ownership System: The Heart of Rust
The ownership system is the cornerstone of Rust’s memory safety. Let’s delve deeper:
- Ownership Rules: Every value in Rust has a single owner – the variable that binds it. When the variable goes out of scope, the value is automatically dropped, freeing the associated memory. This ensures memory is never left dangling or leaked.
- Borrowing: Borrowing allows temporary access to a value without taking ownership. References (
&) and mutable references (&mut) are used for borrowing. The borrow checker, a powerful Rust feature, enforces strict rules to prevent data races and ensure references always point to valid data. - Stack vs. Heap: Understanding these memory regions is crucial in Rust. The stack is a fixed-size memory area used for local variables and function calls. It’s fast but short-lived. The heap is a dynamically allocated memory region for larger data structures. Ownership dictates where data resides: stack for small, short-lived data, and heap for larger, long-lived data.
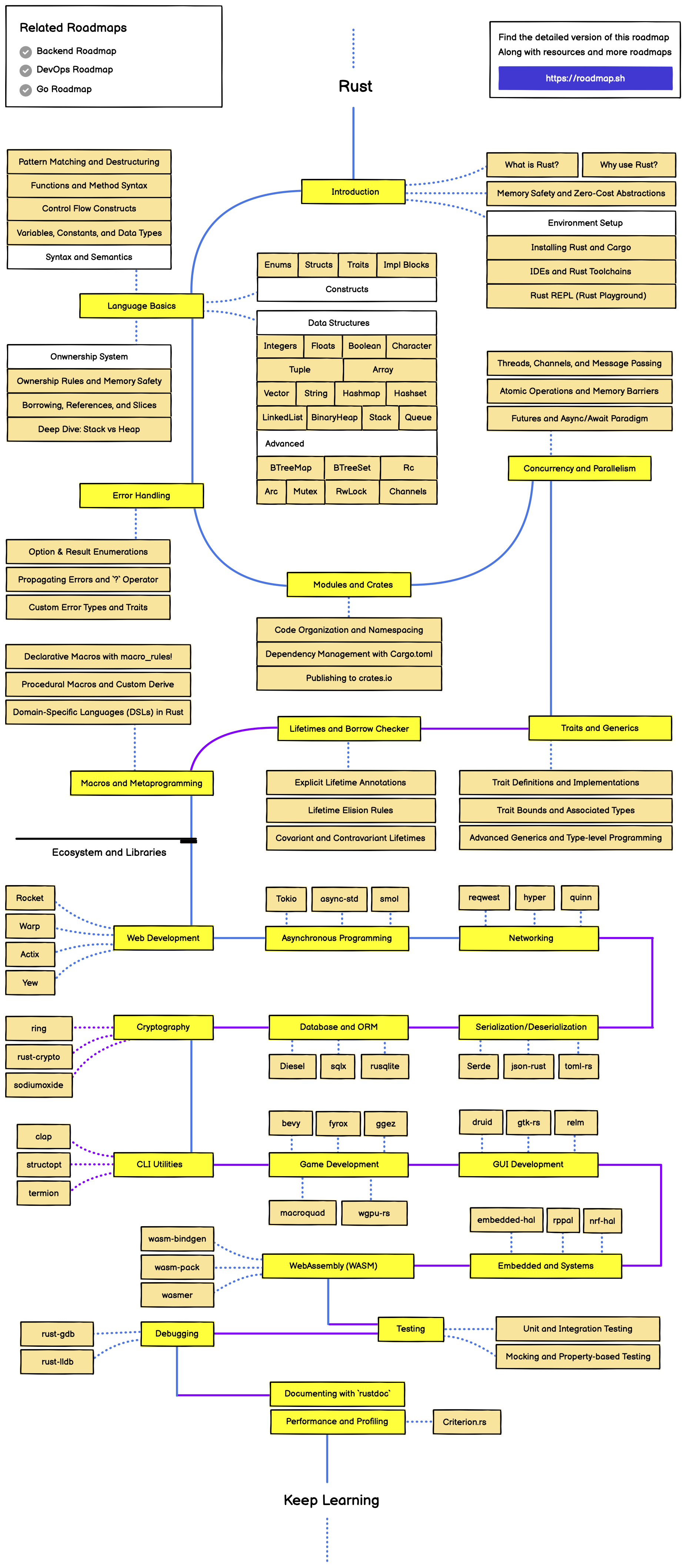
Rust programming language learning roadmap
Beyond the Basics: Advanced Features
- Error Handling: Rust adopts an
Resulttype for error handling. It represents either successful computation with a value or an error with an error code. This promotes explicit error handling, leading to more robust code. - Modules and Crates: Rust promotes code organization through modules and crates. Modules group related code within a source file, while crates are reusable libraries published on https://crates.io/.
- Concurrency and Parallelism: Rust provides mechanisms for writing concurrent and parallel programs. Channels and mutexes enable safe communication and synchronization between threads, allowing efficient utilization of multi-core processors.
- Traits and Generics: Traits define shared behaviors for different types, promoting code reusability. Generics allow writing functions and data structures that work with various types, enhancing code flexibility.
- Lifetimes and Borrow Checker: Lifetimes specify the lifetime of references in Rust. The borrow checker enforces rules ensuring references are valid for their intended usage duration. This prevents data races and memory unsafety issues.
Rust’s Reach: Applications Across Domains
- Web Development: Frameworks like Rocket and Actix utilize Rust’s speed and safety for building high-performance web services and APIs.
- Asynchronous Programming: Async/await syntax allows writing non-blocking, concurrent code, making Rust perfect for building scalable network applications.
- Networking: Libraries like Tokio provide efficient tools for building networking applications requiring low latency and high throughput.
- Serialization and Deserialization: Rust’s data structures map well to various data formats like JSON and CBOR, making it suitable for data exchange tasks.
- Databases: Several database libraries like Diesel offer safe and performant database access from Rust applications.
- Cryptography: Rust’s strong typing and memory safety make it ideal for building secure cryptographic systems.
- Game Development: Game engines like Amethyst leverage Rust’s performance and safety for creating high-fidelity games.
- Embedded Systems: Rust’s resource-efficiency and deterministic memory management make it a compelling choice for resource-constrained embedded systems.